
MKDT group — 次世代インフラ戦略
私たちが次世代データAI基盤に
取り組む理由
OSSとハイブリッド環境を駆使した、ベンダーロックインなき汎用データプラットフォームの構築へ。
生成AIや機械学習の急速な普及によって、企業経営における「データ」の重要性はかつてないほど高まっています。AIの精度はデータの質と量に直結する——そのことを私たちは強く実感しており、MKDT groupとして次世代のデータAI基盤の構築に本格的に取り組み始めました。
このブログでは、私たちがこのプロジェクトに取り組む背景と、その具体的なアーキテクチャ、そして目指すビジネス価値についてお伝えします。
なぜ今、データ基盤なのか
AI時代において、データを持つ企業と持たない企業の差は急速に拡大しています。しかし多くの企業では、部門ごとにシステムがバラバラに存在する「データのサイロ化」が深刻な足かせになっています。
— 01
コストの肥大化
各部門が個別システムを維持することで、運用コストが際限なく増大し続けている。
— 02
横断分析の不可能
データが散在し、企業横断的な分析・AI活用が事実上不可能な状態に陥っている。
— 03
意思決定の遅延
レポート作成に時間がかかり、リアルタイムな経営判断ができない。Excelの手作業が今も残る。
これらの課題を根本から解決するために、私たちはすべてのデータを一箇所に集約し、共通のAI・分析エンジンで活用できる「共通データ基盤」の構築に着手しました。
私たちのアプローチ:「格安」と「高性能」の両立
一般的にデータ基盤の構築というと、高額な商用ライセンスや特定クラウドへの依存が避けられないと思われがちです。しかし私たちは、中立な財団OSS(Apache/CNCF)をフル活用することで、商用ライセンス料ゼロで次世代のデータプラットフォームを実現しようとしています。
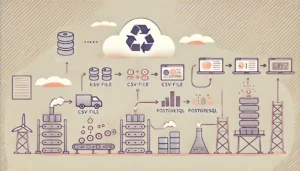
アーキテクチャの全体像
データの流れは以下の5ステップで構成されています。各レイヤーに最適なOSSを採用し、それぞれの役割を明確に分離しています。
01
収集・結合
Apache Kafka大量データをリアルタイムで収集・集約
02
蓄積・高速化
Apache Doris数億件を1秒未満で検索可能に
03
ハイブリッド同期
SeaTunnelAWSへセキュアに転送
04
制御・配信
Apache APISIX外部UI・APIへ安全に配信
05
AI価値化
MLflow + LLM独自AIの育成・運用まで一気通貫
特に注目しているのがApache Dorisです。数億件規模のデータを1秒未満で検索できるこの列指向データベースは、既存のPostgreSQLとも直接連携でき、既存システムへの負荷を最小化しながら段階的に導入できる点が魅力です。
具体的な活用イメージ
① 顧客体験のパーソナライズ(Customer 360)
Webサイトの行動履歴、店舗のPOSデータ、アプリの利用状況——これらバラバラだった情報を基盤にシームレスに統合することで、顧客一人ひとりの解像度を劇的に高めます。最適なタイミングでのマーケティング配信や、LTV(顧客生涯価値)の精密な予測が可能になります。
② IoT・センサーデータの予知保全
工場設備やIoTデバイスから秒間数万件規模で発生するストリーミングデータを、ミリ秒単位で収集・分析します。Apache Kafkaによる異常パターンのリアルタイム検知と、メンテナンス計画の自動最適化により、突発的な稼働停止リスクを未然に防ぎます。
③ 全社横断の経営ダッシュボード
営業・財務・人事・セキュリティログまで、各部門のデータを高速レイクハウスへ集約。手作業によるExcelレポートを完全に撤廃し、LLMを用いた自然言語でのデータ問いかけを実現します。
他社プラットフォームとの違い
| 比較項目 | 一般的な商用製品 | MKDT 次世代データAI基盤 |
|---|---|---|
| コスト構造 | 高額なユーザーライセンス+従量課金 | ✓インフラ実費・OSS運用のみ |
| ベンダーロックイン | 製品固有の機能に縛られ移行が困難 | ✓Apache/CNCFで完全な自由度 |
| データ主権 | 特定パブリッククラウドに依存 | ✓自社DC/AWSをk3sで最適に併用 |
| 処理速度 | クラウド依存・レイテンシが変動 | ✓数億件を1秒未満で処理 |
私たちは「格安」でありながら「高性能」なデータ基盤を自分たちで作り上げることに、技術的な可能性と大きなビジネス価値を感じています。
格安でのデータAI基盤の構築をご検討の方はお問い合わせください
お問い合わせ












コメント